
Top-tier open-source video generation on VBench 2.0 with 12–18× faster inference. SOTA video editing — #1 on OpenVE-Bench, FiVE-Bench, and Reco-Bench, surpassing Kling O1.
Top-tier open-source video generation on VBench 2.0 with 12–18× faster inference. SOTA video editing — #1 on OpenVE-Bench, FiVE-Bench, and Reco-Bench, surpassing Kling O1.
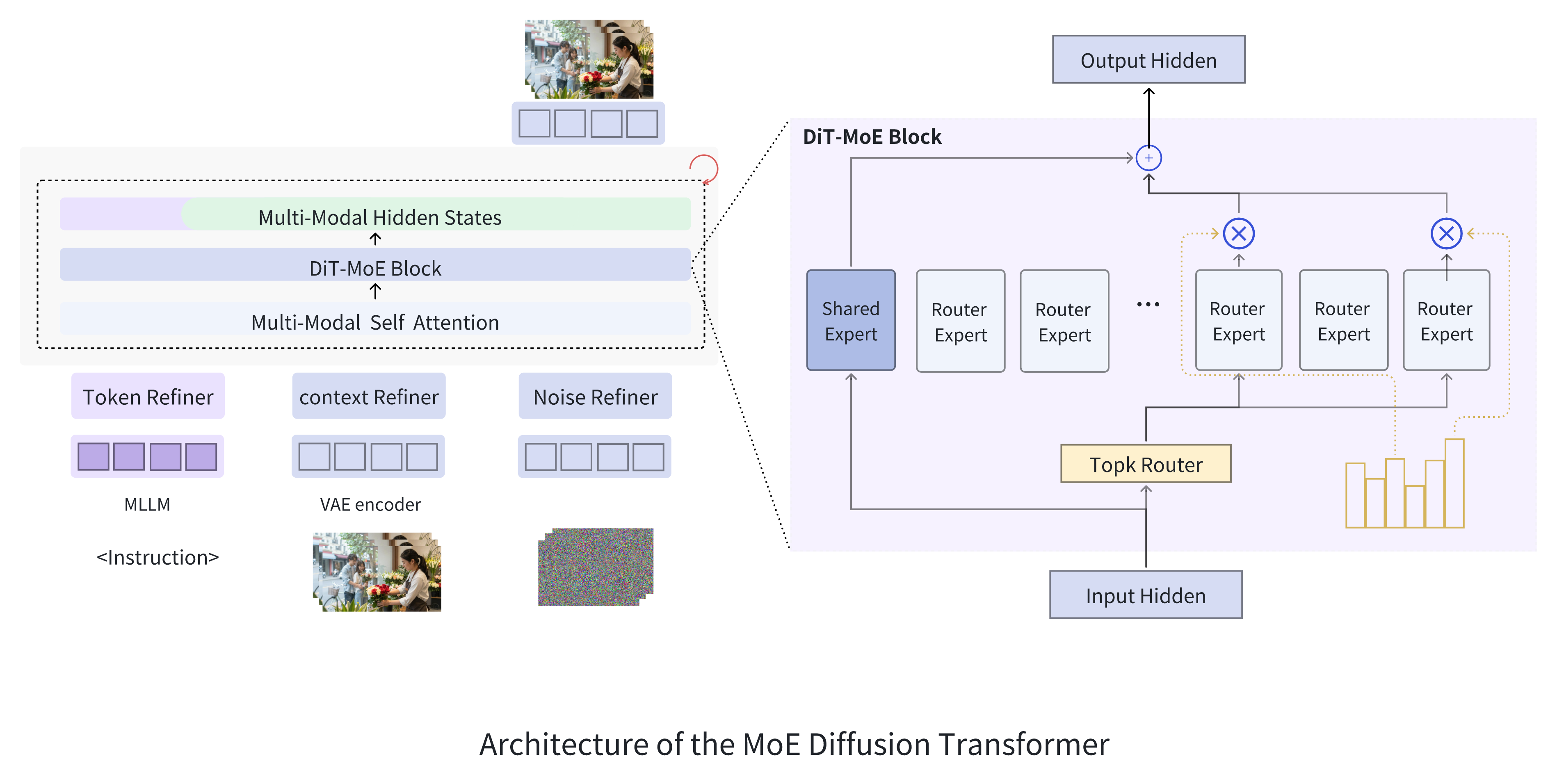
Mamoda2.5 employs a fine-grained Mixture-of-Experts (MoE) design with 128 routed experts and Top-8 routing to scale the DiT backbone to 25B total parameters while activating only ~3B per forward pass (~12%). Combined with the high-compression Wan2.2 VAE (4×16×16), Mamoda2.5 completes 720p 93-frame video generation in 110 seconds on a single device — over 12× faster than Wan2.2 A14B, 5× faster than HunyuanVideo 1.5, and 18× faster than LongCat Video. Ablation studies confirm a ~2.2× convergence speedup over dense models under matched activated parameters.

A single AR-Diffusion framework built on Qwen3-VL-8B for multimodal understanding and an MoE DiT backbone for generation. One unified model supports text-to-image, text-to-video, image editing, and video editing, eliminating the need for separate task-specific models. The 30-step editing model achieves 12.8× faster inference than VInO; with the distilled 4-step model, editing latency drops to just 9.2 seconds — a 95.9× speedup over VInO and 41.7× over OmniVideo2.
@article{mamoda2.5,
title={Mamoda2.5: Enhancing Unified Multimodal Model with DiT-MoE},
author={Mamoda Team},
journal={arXiv preprint arXiv:2605.02641},
year={2025}
}